Data Classifications and Tags¶
last updated on: April 12, 2024¶
Data classification and tagging can be defined as a process in which data is organized into categories so that data may be grouped and accessed in the most efficient way possible.
Nasuni Access Anywhere enables users and automated processes to attach descriptive information to files and folders in the form of metadata tags and data classifications.
Tags¶
A Tag is a generic type of data classification which is the available default classification in Access Anywhere and the only classification available if no others are configured. Metadata tags applied to files within the Tag classification can be a word, a phrase, a date or any string of characters. All of these are examples of valid tag values:
- sensitive data
- PHI
- UK only access
- Dec. 2, 2020
- 2020-09-03
- Marketing
Data Classifications¶
Rather than use the generic 'tag' classification, other data classifications can be created that are appropriate to a business domain or compliance policy.
For example a classification for "Project", or "Confidentiality".
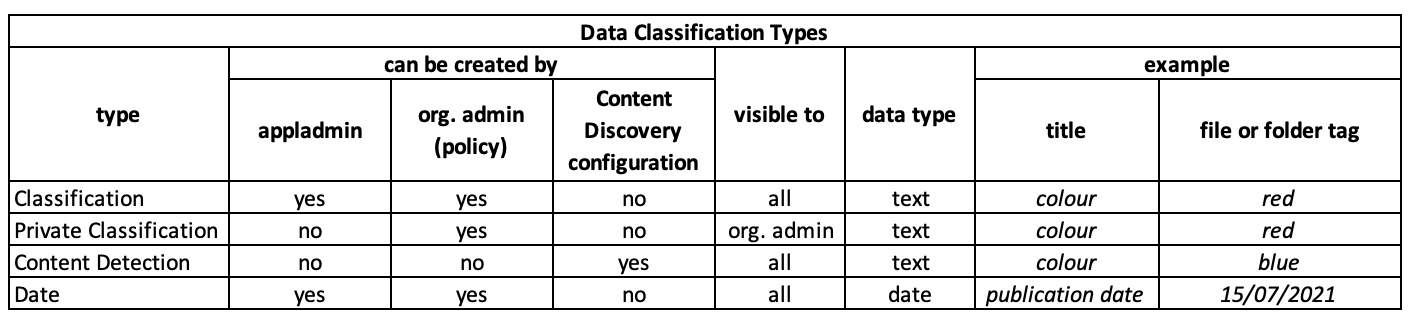
There are four types of data classifications:
- **Classification** - A user defined entry that is used to group a collection of tagged data assets.
- **Private Classification** - Similar to a "Classification" but visible only to the org. admin.
- **Date** - Similar to a "Classification" but the tag's value can only be a date.
- **Content Detection** - Similar to a "Classification" but created automatically by the Content Discovery feature. A Content Detection classification is created for each Content Detection category in the organization's Content Discovery configuration.
Searching with Tags¶
Using the Tag Cloud¶
The Tags tab allows you to sort and view files and folders based on data classification and tag name. Tag prevalence is quickly identified by the tag cloud. The larger the font, the more files with that tag.
Choose a data classification from the dropdown, and hover over a tag name to view the specific number of files with that tag.
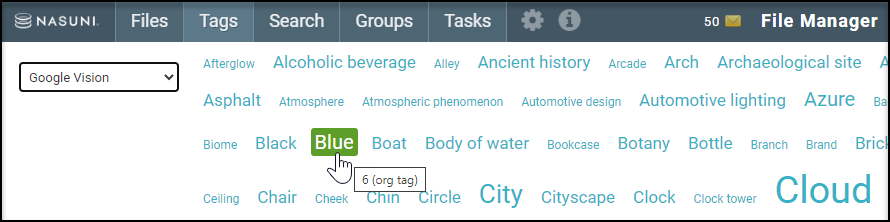
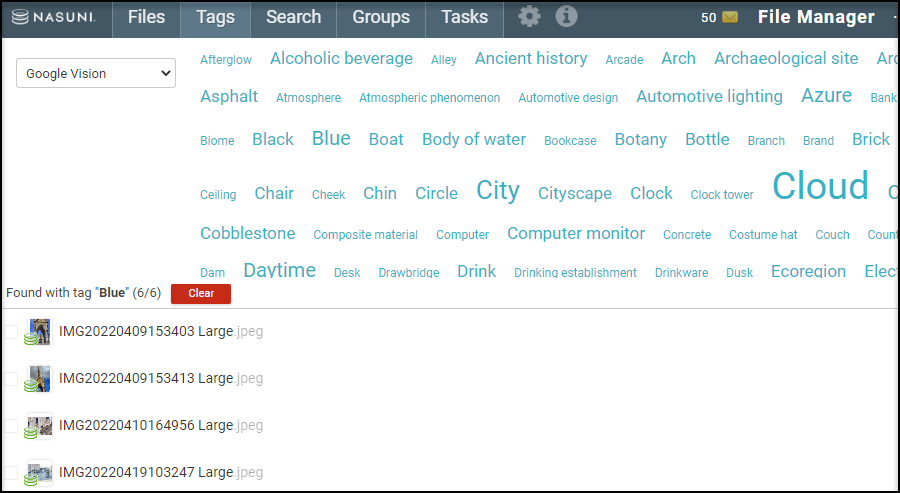
Click a tag name to view the list of files and folders associated with that tag.
Search¶
From the Search tab you can use tags and data classifications as search filters
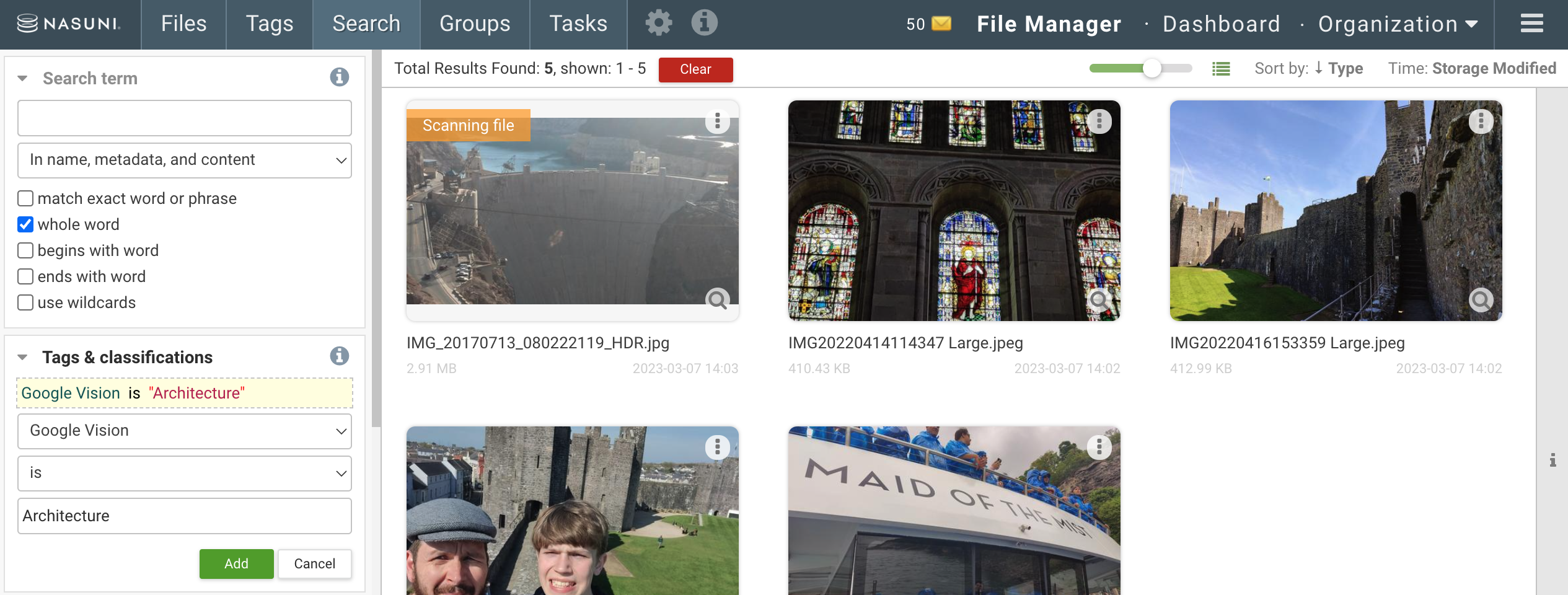 .
.
Adding Tags¶
Adding Tags to Multiple Files or Folders¶
To add a tag to multiple files or folders, follow these steps.
-
Click the tick box located next to each file or folder that needs a tag.
-
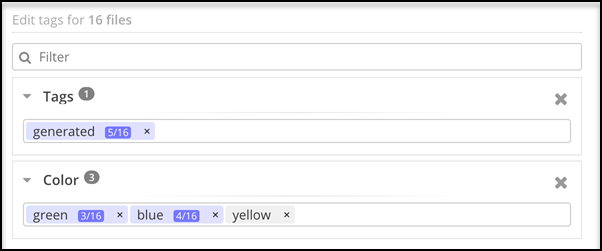
Right-click and select Tags from the list. The Tags dialog box displays all the tags associated with the group of files. The first figure represents the number of files with that tag. The second figure is the total number of files in the folder.
-
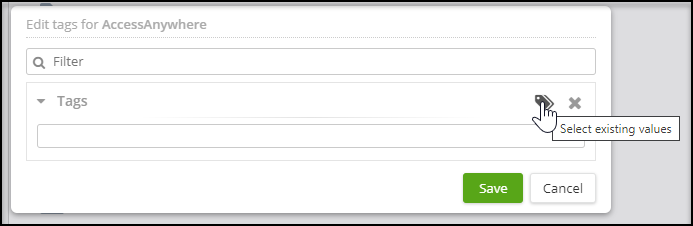
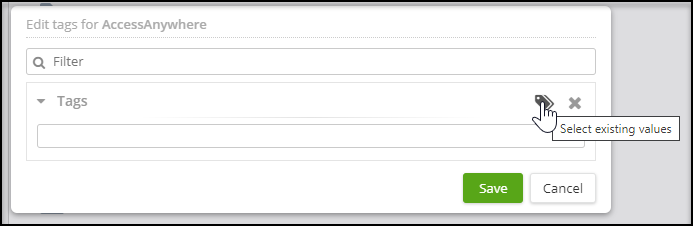
Choose an existing tag or create a new one. a. Choosing an existing tag: Click the tags icon and choose one or more tags from the list. Click Select.
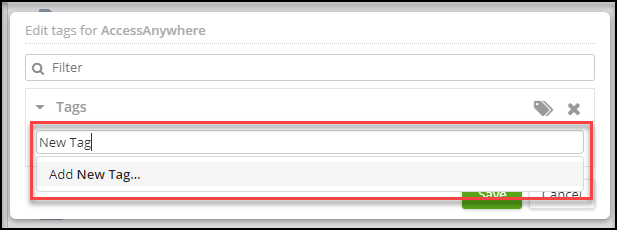
 b. Creating a new tag: Using the Tags field, enter a new tag name and click Save.
b. Creating a new tag: Using the Tags field, enter a new tag name and click Save.
- Click Save to finish.
Adding a Tag to a File or Folder¶
To add a tag to a file or folder, follow these steps.
-
Right-click over the file or folder.
-
Select Tags from the list.
-
Choose an existing tag or create a new one. a. Choosing an existing tag: Click the tags icon and choose one or more tags from the list. Click Select.
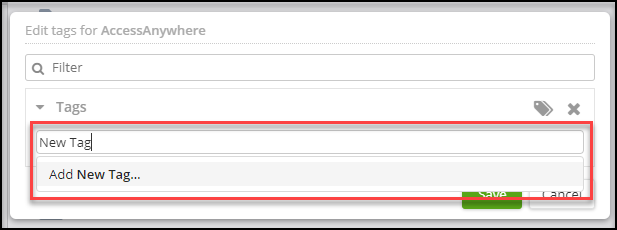
 b. Creating a new tag: Using the Tags field, enter a new tag name and click Save.
b. Creating a new tag: Using the Tags field, enter a new tag name and click Save.
-
Click Save to finish.
Uploading Files¶
To upload a file or folder, follow these steps.
- Click Upload files and select Single Upload. 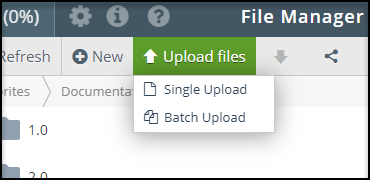
- Click Choose File and select a file or folder to upload.
- Enter a File Name and a Short description of the file.
- In the Tag field, either enter one or more new tag names or click the tag icon to choose one or more from the list. Note: If adding multiple new tag names, separate each tag with a comma. 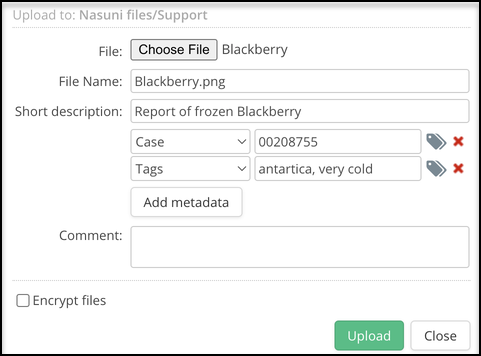 - (Optional) Enter a Comment.
- Click Upload**.
- (Optional) Enter a Comment.
- Click Upload**.
Uploading Multiple Files¶
To upload a batch of files or folders, follow these steps.
- Click Upload files and select Batch Upload.
- Either click Browse files and select the files or folders to upload or drag and drop your files or folders into the shaded area. 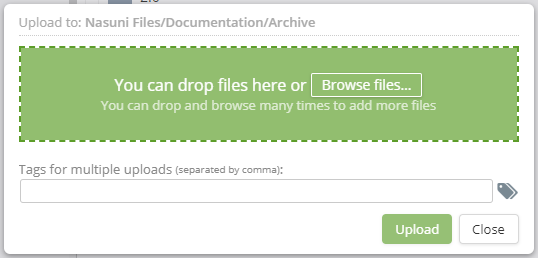 - In the Tag field, either enter one or more new tag names or click the tag icon to choose one or more from the list. Note: If adding multiple new tag names, separate each tag with a comma.
- In the Tag field, either enter one or more new tag names or click the tag icon to choose one or more from the list. Note: If adding multiple new tag names, separate each tag with a comma. 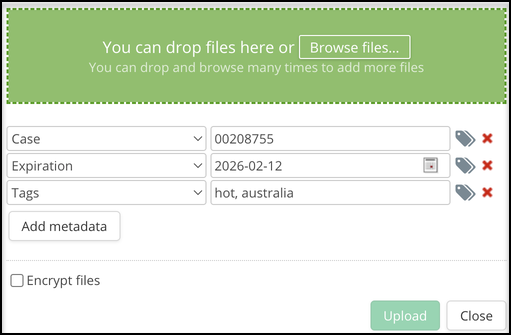 - Click Upload**.
- Click Upload**.
File and Folder Operations¶
Copies and Moves¶
When a file or folder is moved or copied uploaded to a working directory (as opposed to trash), the new file in the destination folder will have the source file’s tags and classifications.
Versions¶
When a version file is promoted to be the new head file the new head will have the previous head’s tags and classifications.
When the head of a version file is pushed down by a newer copy of the file, the pushed down version will retain its tags and classifications.
Restoring from Trash¶
When a file or folder is moved to trash, either directly or as the result of another operation, it retains its tags and classifications.
When a file or folder is restored from trash and does not overwrite another file or folder of the same name in the same location, the newly restored file or folder will have the trash file or folder’s tags and classifications.
When a file or folder is restored from trash and overwrites another file or folder of the same name in the same location, the newly restored file or folder will have the overwritten file or folder’s tags and classifications.
Exporting Tags and Classifications¶
Tags and classifications are stored in Access Anywhere as external metadata. This metadata can be modified, deleted and accessed via the Api. Tags and classifications can also be exported from Search results. Choose "Export" and the "Compliance" report.