Amazon S3 Storage¶
Last updated on November 16, 2021¶
Amazon S3 provides a simple web services interface that can be used to store and retrieve any amount of data, at any time, from anywhere on the web. It gives any developer access to the same highly scalable, reliable, secure, fast, inexpensive infrastructure that Amazon uses to run its own global network of websites. The service aims to maximize the benefits of scale and to pass those benefits on to developers.
The Access Anywhere enables easy access, management, use of Amazon S3 storage to anyone, not just developers.
The AWS GovCloud (US) is also supported. When adding the provider choose Amazon S3 GovCloud US Non-FIPS or FIPS.
See also /Amazons3Glacier.
See also /Cloudproviders/S3Compatible
1 Adding the S3 Cloud¶
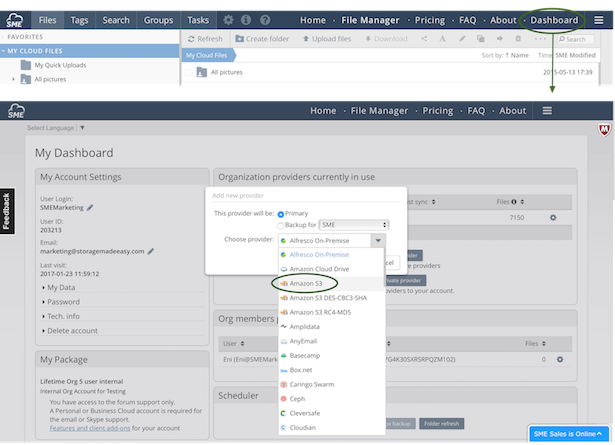
You can choose to add the the Amazon S3 Service to Access Anywhere by first navigating to your Cloud Dashboard Menu>My Dashboard tab and then choosing the Add new Provider and following the wizard therein.
2 Obtaining your Amazon Credentials¶
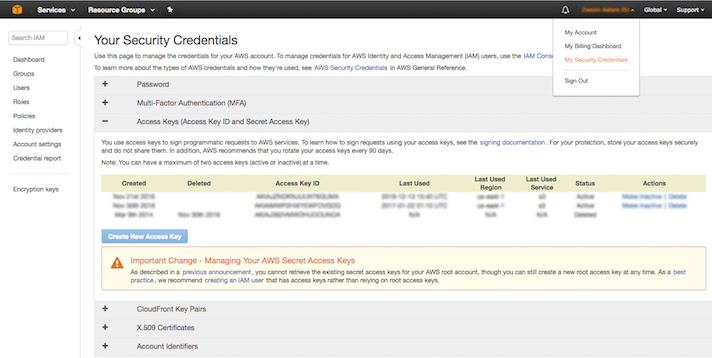
Login to your Amazon Web Services Account. From the Dashboard view click on the account link and then click on the security credentials link. It is from here that you will be able to obtain the relevant keys needed to connect your Amazon S3 Account with Access Anywhere.
3 Entering your Amazon Details¶
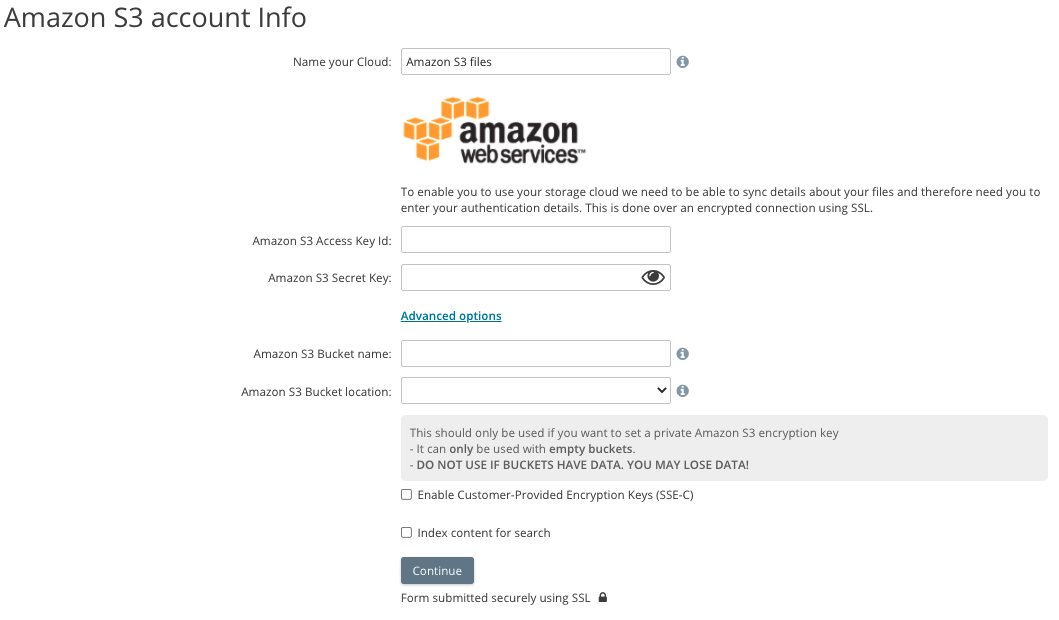
From the Wizard that is launched when clicking the "add new provider" from the DashBoard enter the Amazon S3 keys that you retrieved from the prior step and click 'continue'.
If you have a problem authenticating consider re-generating your secret key from your Amazon Web Services Account.
If your account has access to Access Anywhere's Content Search feature and you want the contents of the files stored on this provider to be indexed, tick the box labelled "Index content for search".
Advanced S3 Options¶
The advanced option section can be exposed or hidden by clicking on "Advanced options".
The "Amazon S3 Bucket name" and "Amazon S3 Bucket location" settings are provided for the case where your S3 credentials do not allow you to list the buckets in the S3 account you are using, but give you access to one of the buckets in that account. Enter the bucket name and region here.
The "Enable Customer-Provided Encryption Keys (SSE-C)" provides access to S3's SSE-C option. If you select this option then you will have to provide an encryption phrase which SSE-C will use to encrypt the files that are uploaded to this provider through Access Anywhere.
- Note that if SSE-C is enabled on Access Anywhere it is assumed that all files in the bucket are SSE-C encrypted and Access Anywhere will not be able to ready objects they are not SSE-C encrypted.
4 Selecting Buckets¶
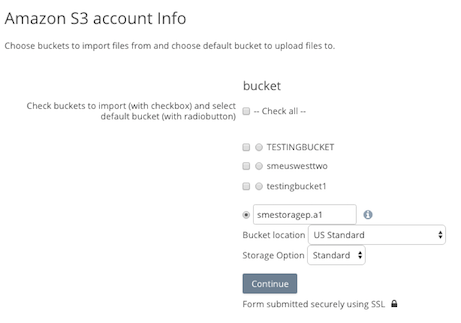
After you enter your authentication details and these are accepted Access Anywhere will discover any S3 buckets that are available. You can choose which buckets you wish to add to your Account, and which will be the default bucket. As part of this process you can choose to create a new default bucket if you wish, and also choose the reason.
Any buckets you choose not to index / sync will not be available to be worked with and you would need to go back to the S3 settings from the DashBoard to add them to your account. This is also the case with any new buckets you add directly from S3.
If S3 is selected as the primary provider for Access Anywhere then the default bucket will be used for interactions with Smart Folders.
5 Indexing / Syncing file information¶
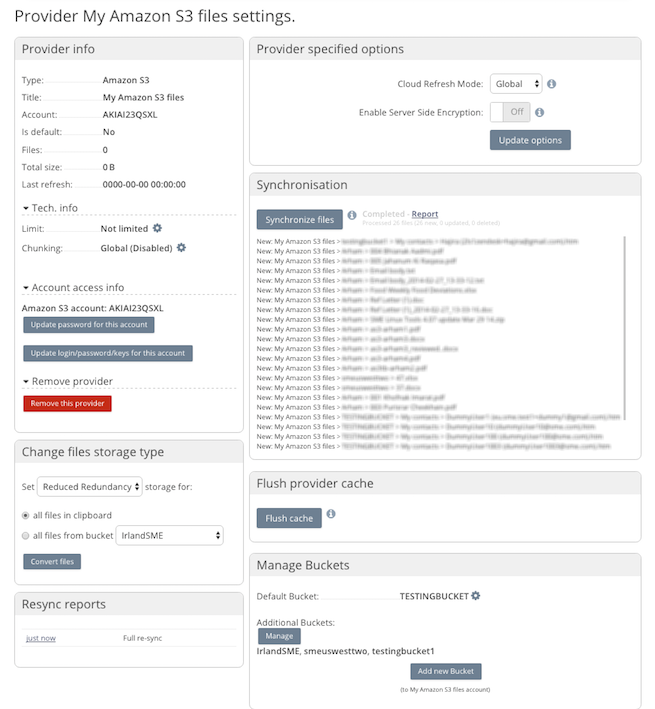
After your authentication has been verified and you have chosen the buckets to work with you will be required to sync your meta data which enables Access Anywhere to interact with your files. You can choose to do this directly in the browser in which case you need to keep the browser open until it completes, or you can choose to have the service do this server-side. You will be still notified in the browser but if you close the browser the meta-sync will continue.
6 Post Sync report¶
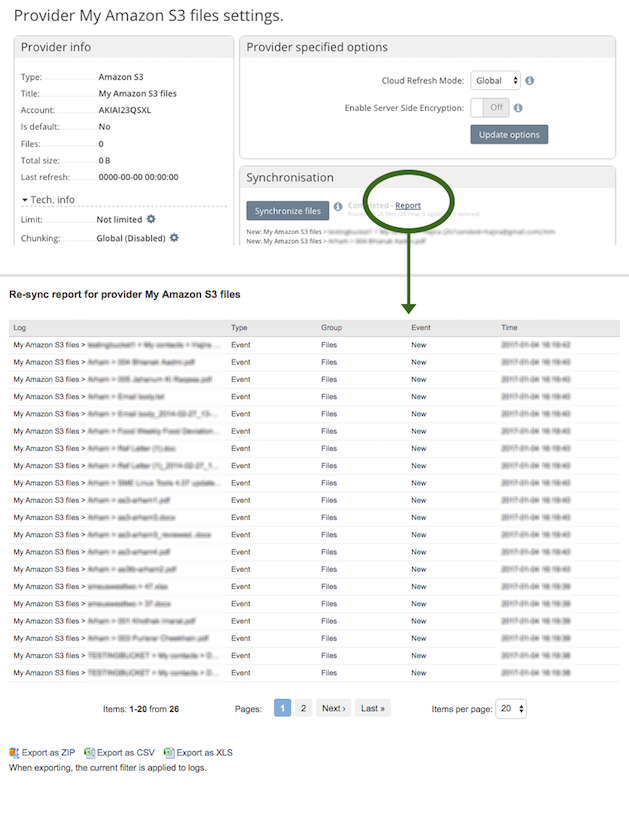
When the sync / index has completed you can choose to access the report of what was indexed.
At this point your files can be accessed and managed directly from the Cloud File Manager and also the different desktop and mobile access clients.
7 Amazon S3 Settings¶
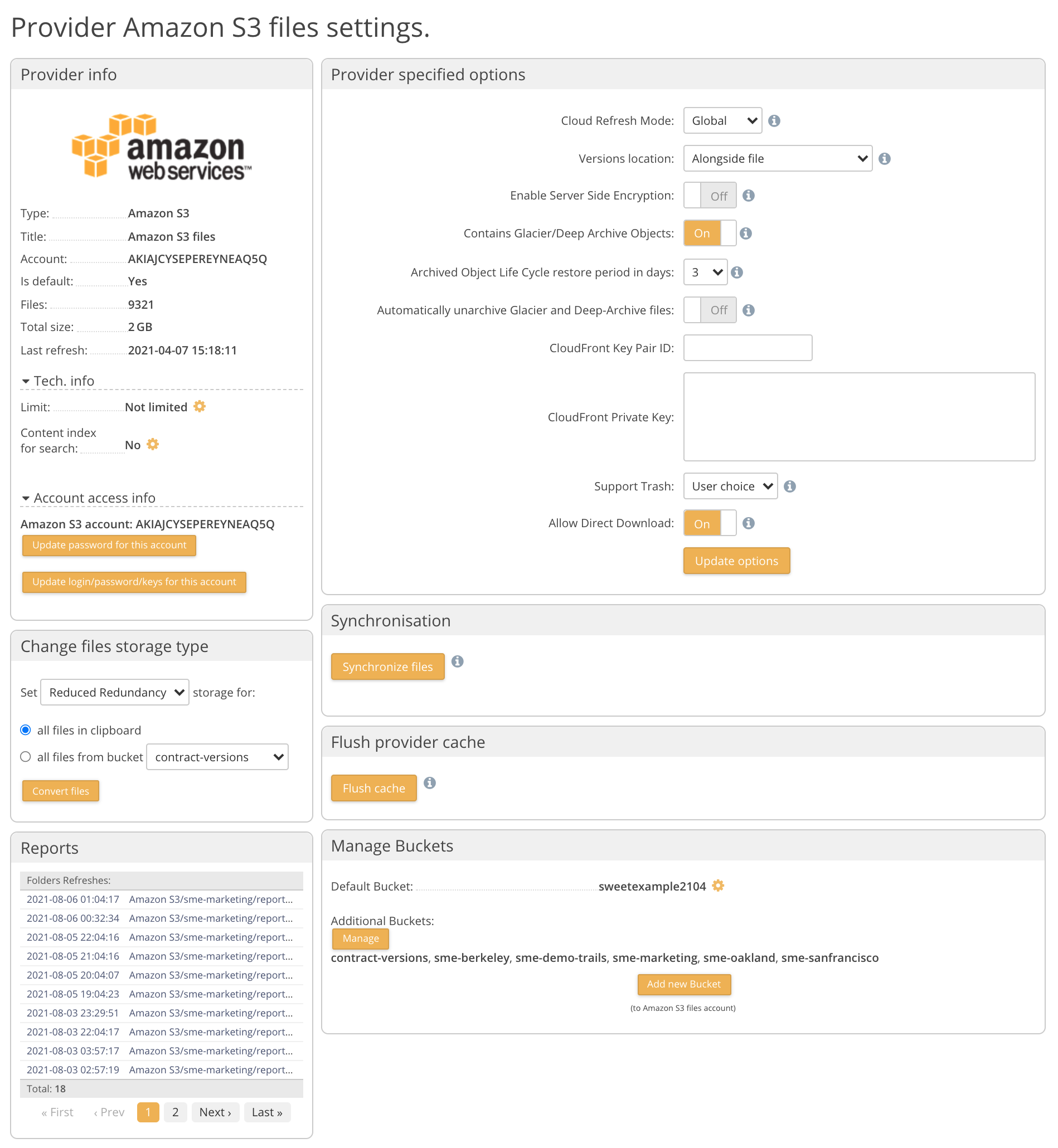
The S3 settings can be accessed from navigating to the 'Dashboard->Amazon S3 Settings link.
From here you can:
- Choose to totally remove the provider which removes all metadata associated with your account from S3.
- Enable Amazon S3 server-side encryption for your files
- Add / Manage buckets - Activate Reduced Redundancy options for buckets.
You can also choose to resync the meta-data of the provider
Changing Access Keys¶
You can also enter both the new Access Key and Secret Key here if you are rotating your Access Keys. The keys should be in the same AWS account with access to the same buckets.
Direct Download¶
Enabling Direct Download allows client applications and share links to download objects directly from the AWS servers (via signed URLs) rather than through Access Anywhere.
Direct download is not supported when Customer-Provided Encryption Keys (SSE-C) are enabled, nor for files stored in Glacier or Glacier Deep Archive.
8 Limiting Access (Optional)¶
To restrict the account's access to only required S3 operations and resources create an custom IAM policy and add to the Amazon user for the account.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListAllMyBuckets",
"s3:AbortMultipartUpload",
"s3:RestoreObject",
"s3:ListBucket",
"s3:DeleteObject",
"s3:GetBucketLocation",
"s3:DeleteBucket"
],
"Resource": "*"
}
]
}
To restrict the account's access to a specific bucket, you could create a policy like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource":"arn:aws:s3:::thisbucketonly"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:RestoreObject"
],
"Resource": "arn:aws:s3:::thisbucketonly/*"
},
{
"Effect": "Allow",
"Action": "s3:ListAllMyBuckets",
"Resource": "*"
}
]
}
9 Working with S3 files¶
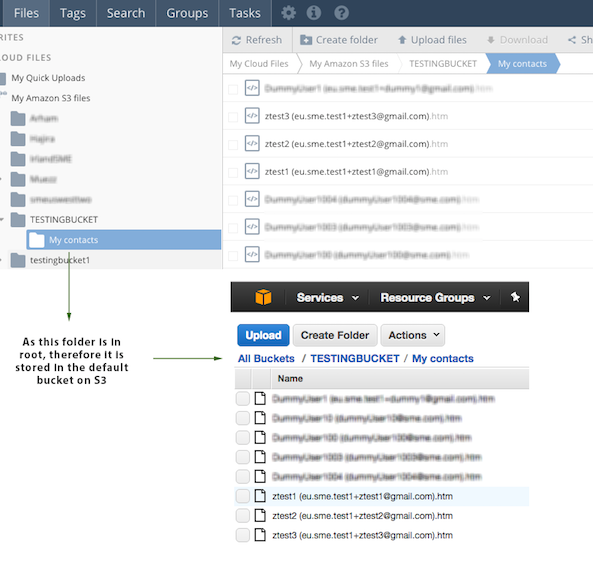
When you work with Amazon S3 files you can choose to do so from the web file manager or any of the access clients Apps.
When you first import the meta-data from Amazon S3 you will be asked to set a default bucket. A default bucket is what is used if you add data to any smart folders such as 'My Syncs' etc. When you add data to these folders then the data actually resides on your default S3 bucket that you chose at setup. For example if you added data to the smart folder 'My Syncs' then in your default S3 bucket there would be a folder created called 'My Syncs' where this information would reside.
Similarly if you create something in the root of "My Amazon S3 files" or whatever else you choose to call this we will automatically try to create a bucket, but if the bucket name is taken the default behaviour is to create a folder, and this folder would reside in your default bucket. If you want precise control over only adding a new bucket then navigate to your S3 Settings from your DashBoard and add a new bucket from here.
Any folders/files that you create in normal buckets are stored directly within the buckets on S3. The rules above only apply when using smart folders, which you can choose to use or not to use.
Also we don't do anything to your files, such as other S3 provider can do ie. we don't rename them or apply an encoding to the file name etc. Your files are stored with the same name and format as you upload them
We also keep additional meta-data as compared to S3. An example of this is the local timestamp. If you upload files to S3 using our desktop sync tools then we are able to keep the local timestamp which direct uploads to S3 do not.
For objects uploaded to S3 the metadata property Content-Type is added based on the file extension.
Provider Requirements¶
Restrictions¶
The Amazon S3 provider doesn't impose limits such as number of buckets, object size, number of parts (for multi-part upload) and length of object keys except where the S3 API is also limited.
Bucket names are also not restricted with the exception that bucket names with dots (periods) are not supported due to security issues with virtual-host-style addressing over HTTPS.
If S3 restricts an operation, and an error is returned to Access Anywhere, an error will be returned to the client application.
Rate Limiting¶
Occasionally Amazon S3 may limit the rate at which it processes requests. This page: Access Anywhere Handling of Rate-Limiting Storage Providers explains how Access Anywhere responds to rate limiting.